
本文最后更新于1 分钟前,文中所描述的信息可能已发生改变。
前言
自23年OpenAI的ChatGPT问世依赖,AI、大模型、文生图、GPT已经是一个老生常谈的话题了。目前AI发展主要分为两个热门的赛道。
一个是以GPT为主Transformer架构的文本衍生模型,可以基于聊天式的方式,与大语言模型进行交互,打破了以前人们对AI回复内容“不能直视”的常态。因为ChatGPT的问世,这条赛道可以说是前景非常光明,而且特别有意义。
而另一个则是以闭源模型Midjourney壮大的文生图模型,顾名思义,它是以一段文本作为输入,基于文本内容,生成相关主题以及元素的图片,现在可以说是网上大部分图片都是AI生成的。midjourney之后StabilityAI开源了基于Diffusion架构的文生图扩散模型,一经推出便在社区爆火,无数的开发者,训练师(也就是所谓的炼丹师)迅速涌入,基于最开始的SD1.5模型,训练了大量的优质模型,令这个赛道发展的越来越迅速。后来又推出了SD2.0、SDXL等等一次比一次惊艳。
现如今,Stable Diffusion模型已经可以说是非常成熟了,由AI生成的图片也越来越难以区分真假,这也让很多和设计与艺术相关工作的人们工作效率有了大幅提高。
比如基于现在的Stable Diffusion模型加上其他模型,可以做到如:
- 老照片修复;
- 人脸替换;
- 卡通人物生成;
- 基于照片生成相似度极高的人物图片等等功能。
什么是ComfyUI?
基于上面Stable Diffusion模型,出现了很多的围绕该模型出现的UI界面工具集项目,大大简化了原生模型的使用方式,可以更加方便快速的完成各种各样的功能。 如早期出现的Automatic1111大佬的webui界面,凡是玩开源大模型的基本都有用过它,其集成了很多的功能,可以通过界面操作,很方便的生成或修改图片。甚至集成了模型训练,模型合并等功能,它还可以根据插件的方式,安装各种各样的额外的功能支持。 由于它的傻瓜式操作界面,以及易用性,使得其非常受刚接触AI文生图的小白使用。 界面如下图所示: 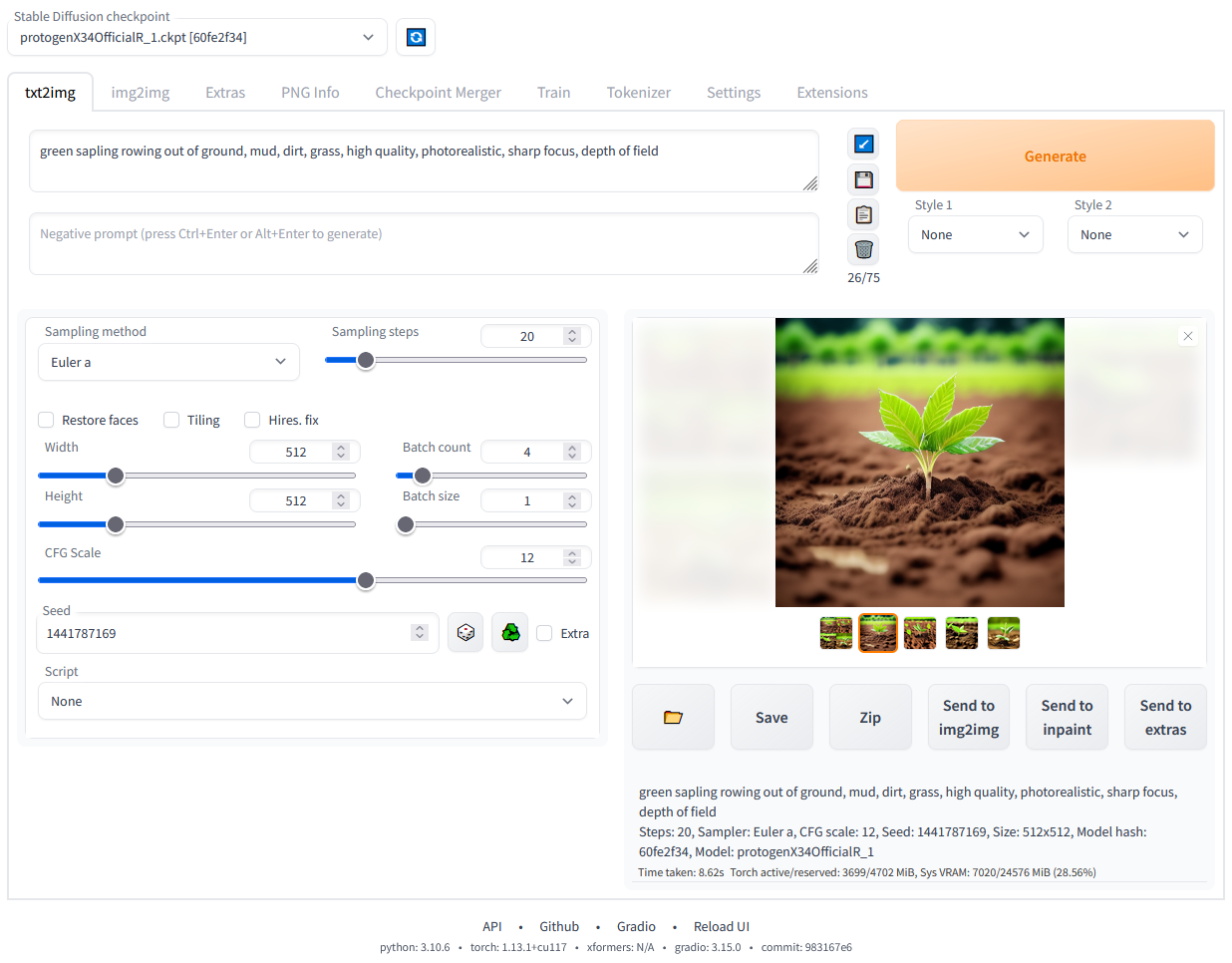
另一个最近越来越火的则是我要讲的基于工作流模式的ComfyUI界面管理器。
与webui不同,它的界面看着很简单(实际上一点也不难),但是相应的可扩展性与自定义化的程度非常高,可以说是将sd的使用提高了一个层级。 它的界面大概是这样: 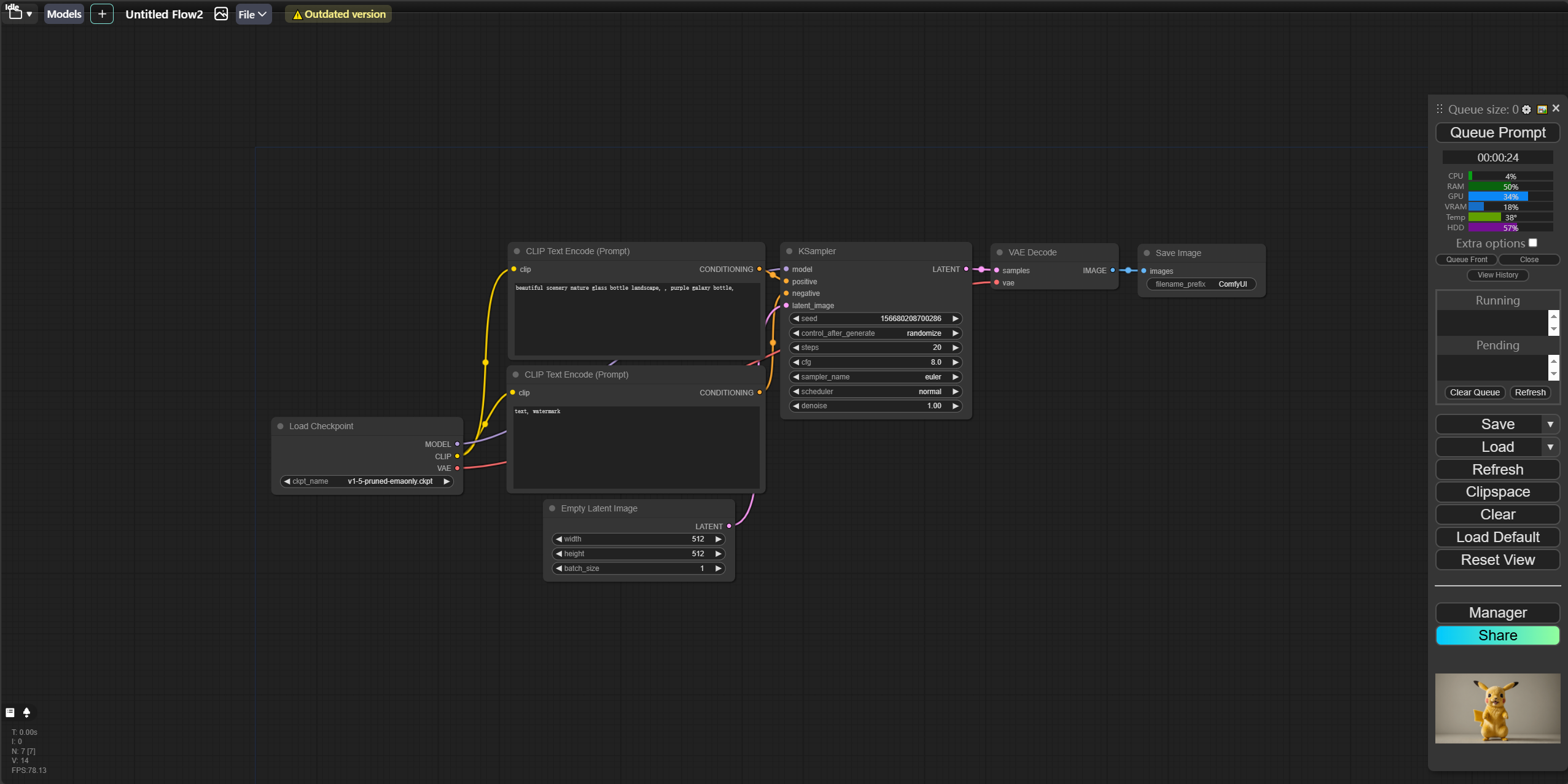
是的,它的界面都是以中间这样的一个个节点组成的,每个节点会执行一个任务,任务结束会自动执行链接的下一个节点的任务,直到最终生成对应的结果。而这一切都是可以自定义的。
安装
ComfyUI的项目地址目前在github,项目地址如下: 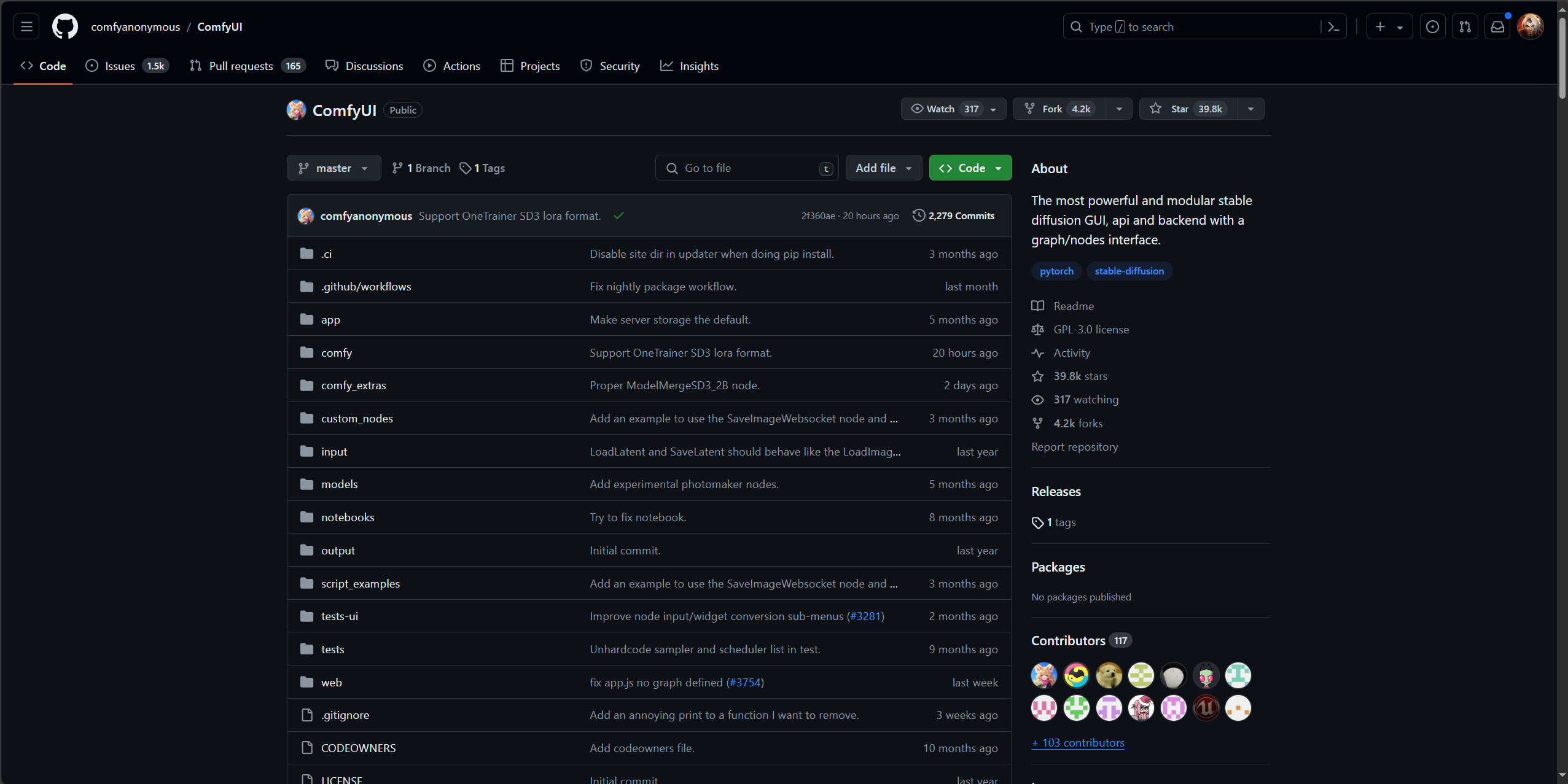
可以看到右上角,这个项目目前已经有39.8k的点赞量,非常火热。
Windows环境安装:
目前对windows环境官方发布了一键启动包,可以直接下载安装包,安装完成后,双击运行即可。 但是只能针对NVidia显卡,如果使用AMD显卡,需要自己编译安装(可能还得额外折腾),只能说A卡对玩AI实在是不友好。
本教程基于windows10,N卡安装ComfyUI: 打开github项目地址,项目地址如下: https://github.com/comfyanonymous/ComfyUI
滚动到Installing部分,点击这里进行下载: 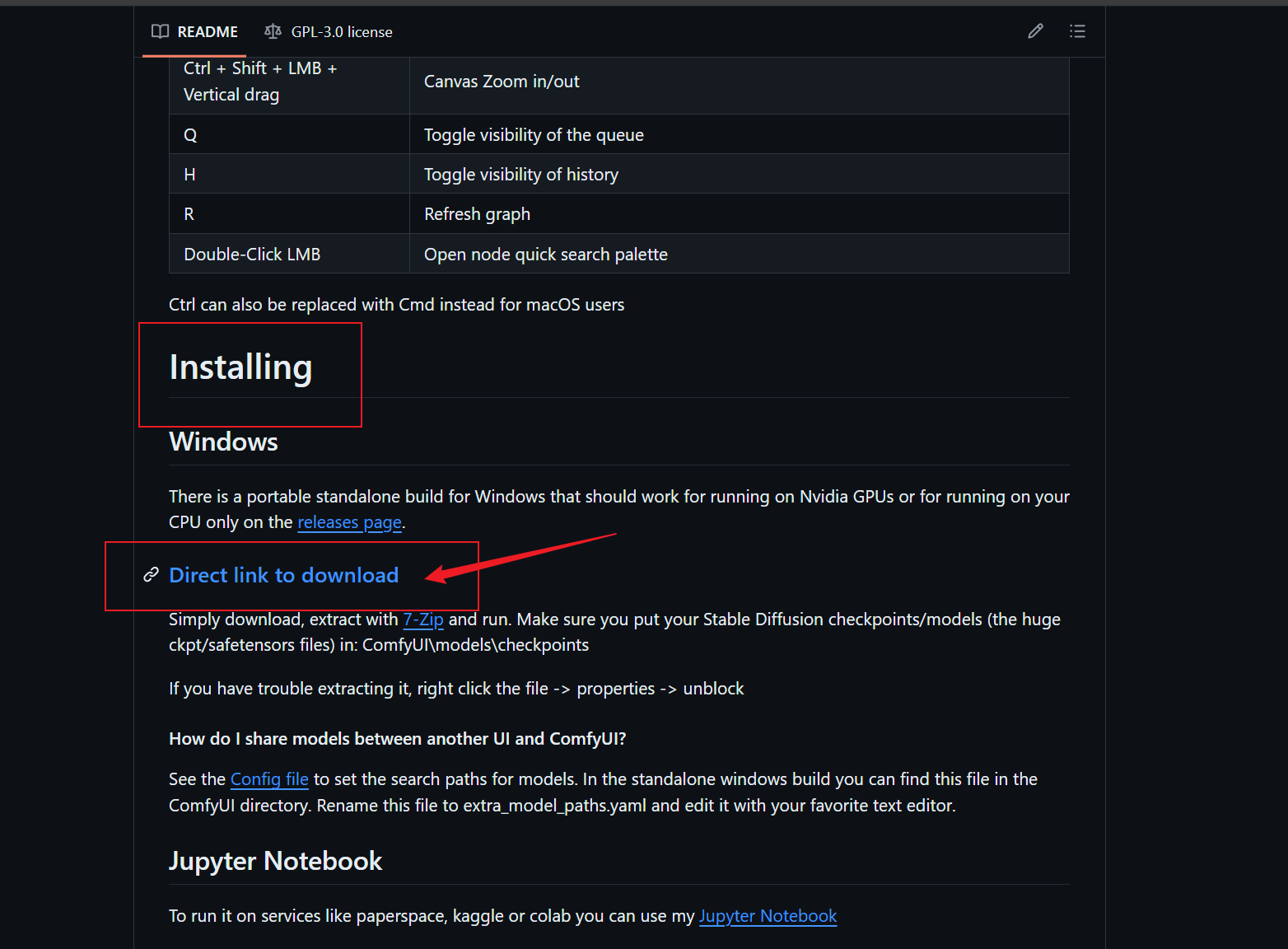
如果由于网络环境不方便下载,可以直接去我的网盘下载:
迅雷云盘ComfyUI压缩包
分享文件:ComfyUI 链接:https://pan.xunlei.com/s/VO04OkgJbwqC-3y-pvClZz1mA1# 提取码:c9tv
下载到本地后,压缩到任意目录即可。
启动
解压后,得到下面的文件列表 
- run_cpu.bat是基于CPU运行,可以进行测试使用,只是速度会非常慢,毕竟是AI大模型,还是比较吃显卡性能的。
- run_nvidia_gpu.bat是基于N卡运行,可以进行正式使用。
- update目录为更新脚本,后续如果节点有报错,或者不支持的话,可以尝试运行其中的bat文件进行升级。
一切准备就绪后,运行run_nvidia_gpu.bat启动ComfyUI。 如果没有问题的话,就会显示如下内容: 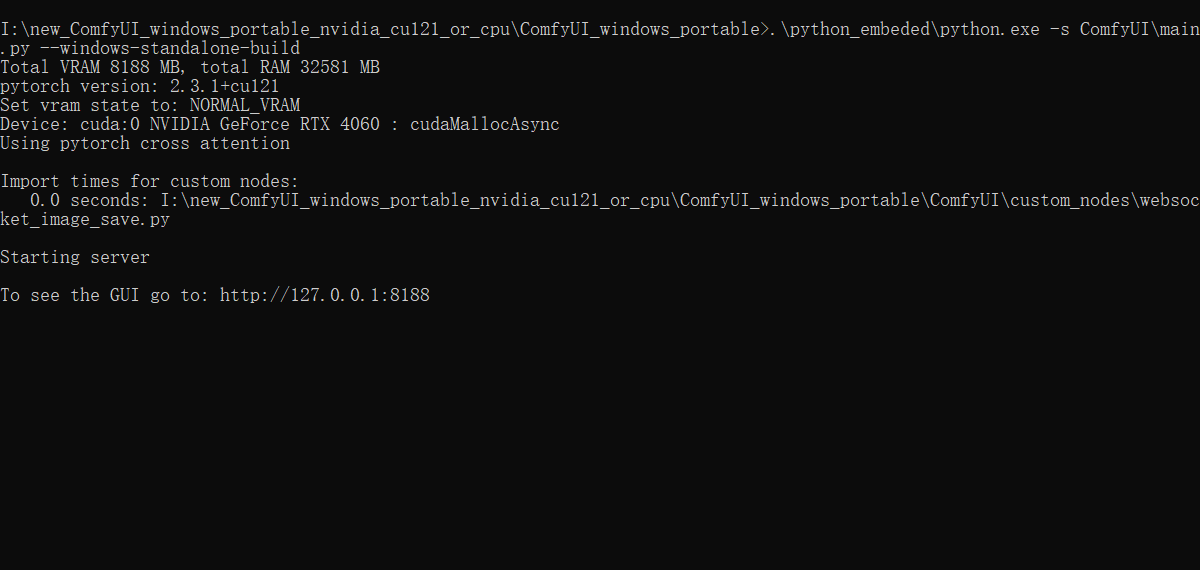
当看到上面的内容,浏览器会自动打开http://127.0.0.1:8188/ 如下图所示: 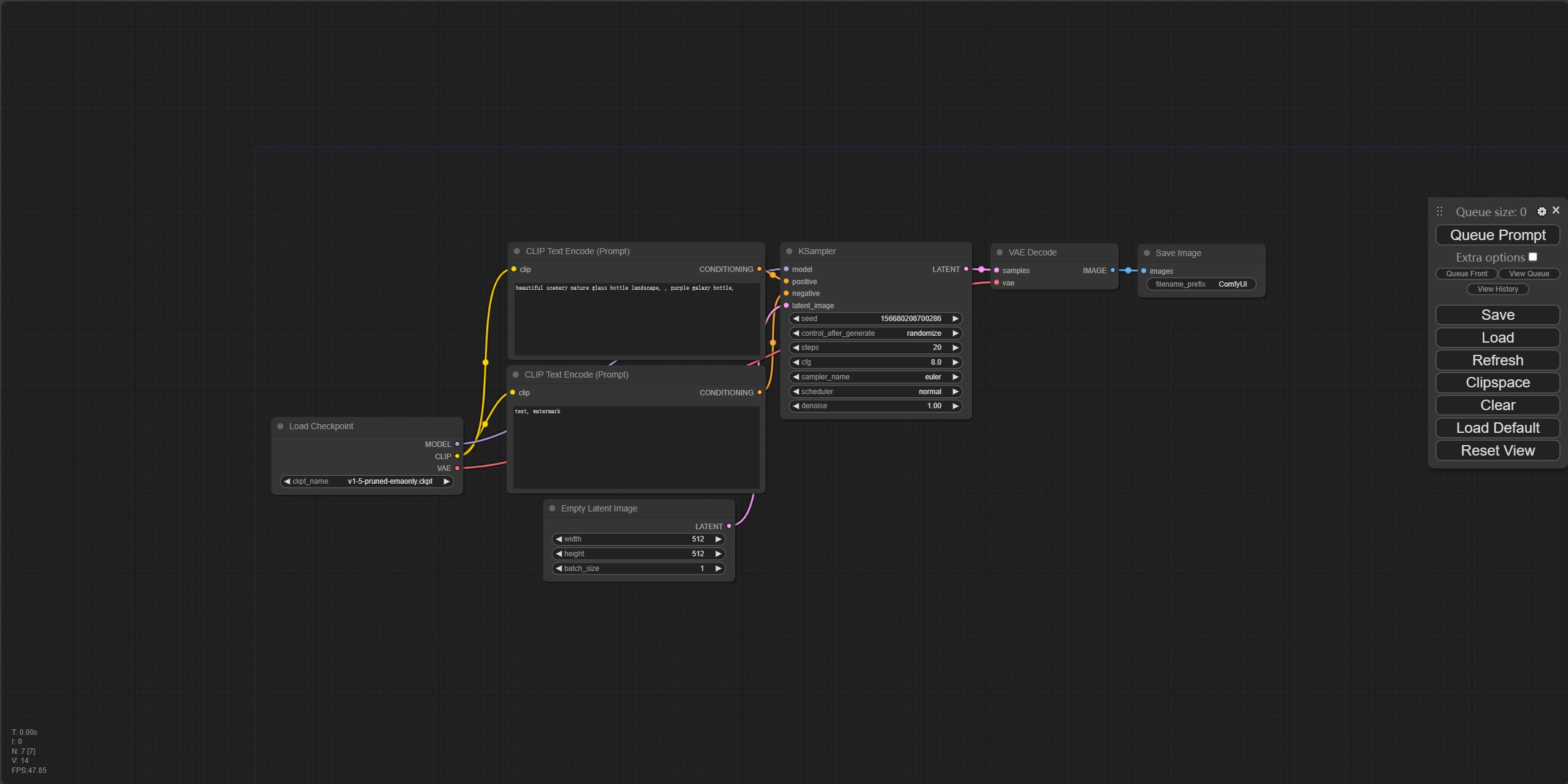
ComfyUI的界面就搭建好了,接下来就可以开始使用啦。
开始文生图之旅
默认会打开图中所示的一个基本工作流,这个工作流包含了最基本的文生图流程。 包含了模型的加载,提示词的输入,根据采样器生成对应的图片,以及保存图片到本地。
- 启动工作流 点击右边的Queue Prompt按钮开始运行以上工作流。 不出意外的话,肯定会报下面的错误:
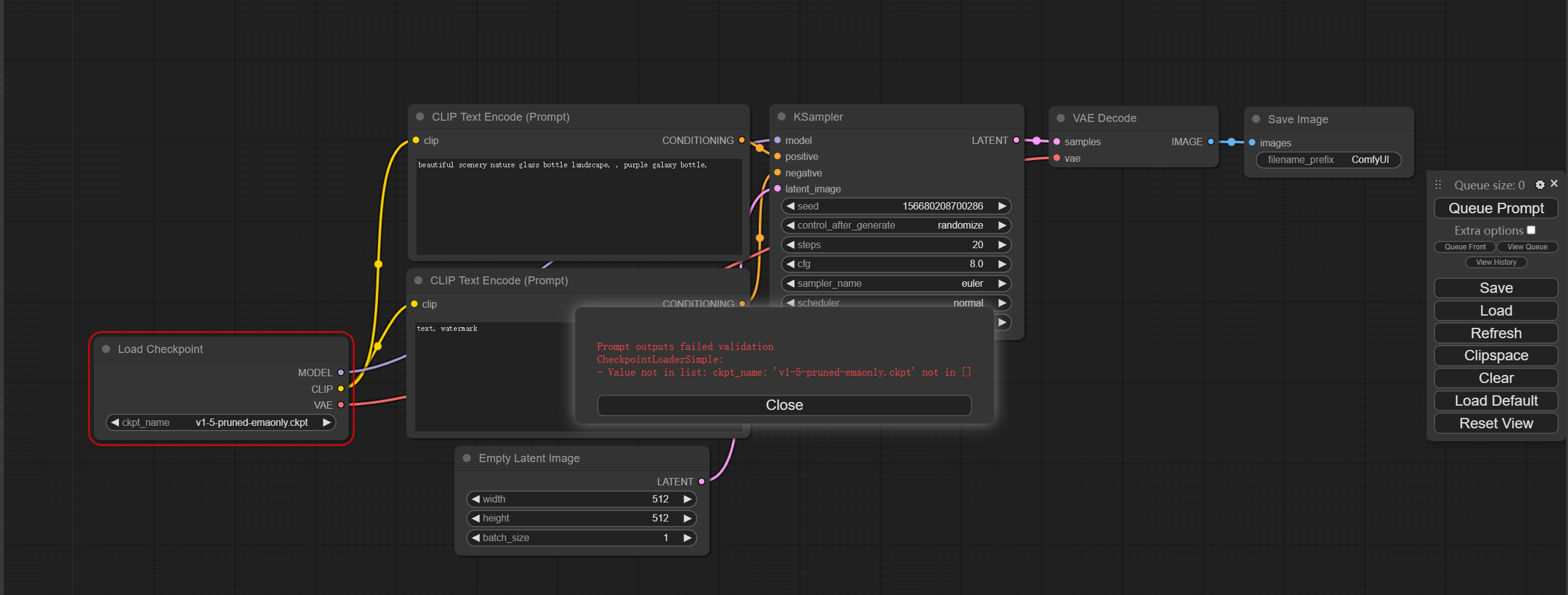
这是因为ComfyUI默认使用的是Stable Diffusion 1.5模型,而现在项目中还没有下载模型文件,因为上面说了,ComfyUI是一个界面管理器,所以它本身并不包含模型,需要我们手动下载。
- 下载模型
https://civitai.com/models/112902?modelVersionId=351306
上面的链接是有名的sd模型社区,里面包含了很丰富的模型,包括Stable Diffusion 1.5,Stable Diffusion 2.1,Stable Diffusion 2.0等等。 这是一个基于SDXL的模型,自带了Lighting模型,可以加速生成速度,能节省生命的浪费,哈哈哈。
如果由于网络原因没法下载,上面的迅雷网盘中包含了该模型的链接,可直接下载。
下载后,将safetensor文件放到ComfyUI_windows_portable\ComfyUI\models\checkpoints目录下,之后重新启动ComfyUI即可。
- 重新运行工作流
点击如下模型载入节点,将默认的1.5模型换为我们下载的模型 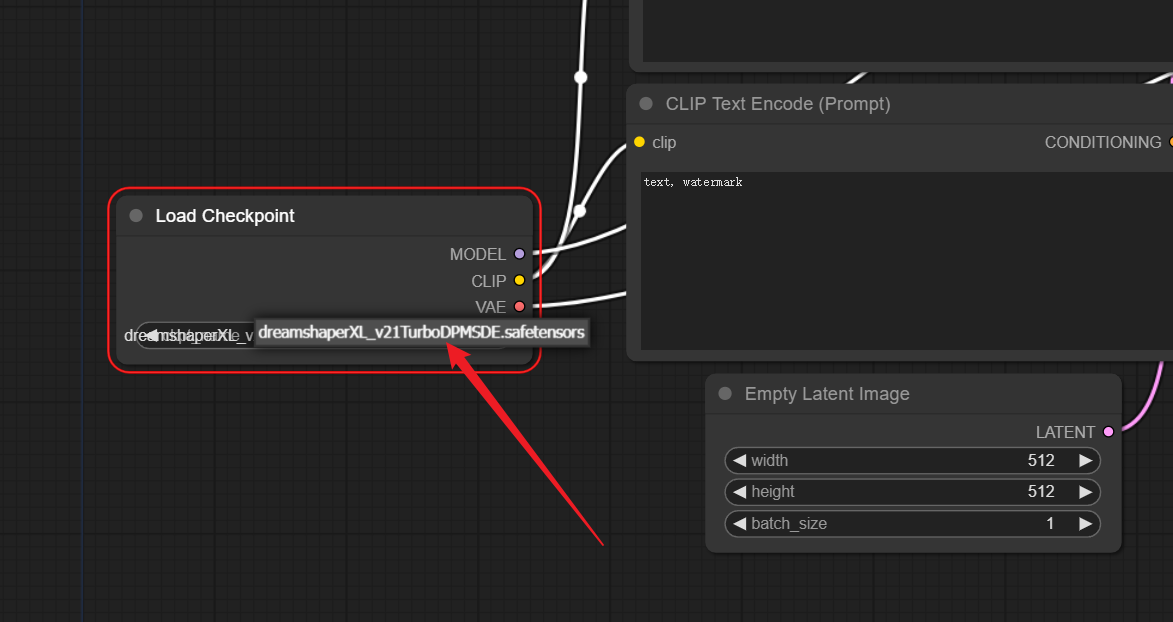
之后重新运行工作流即可。
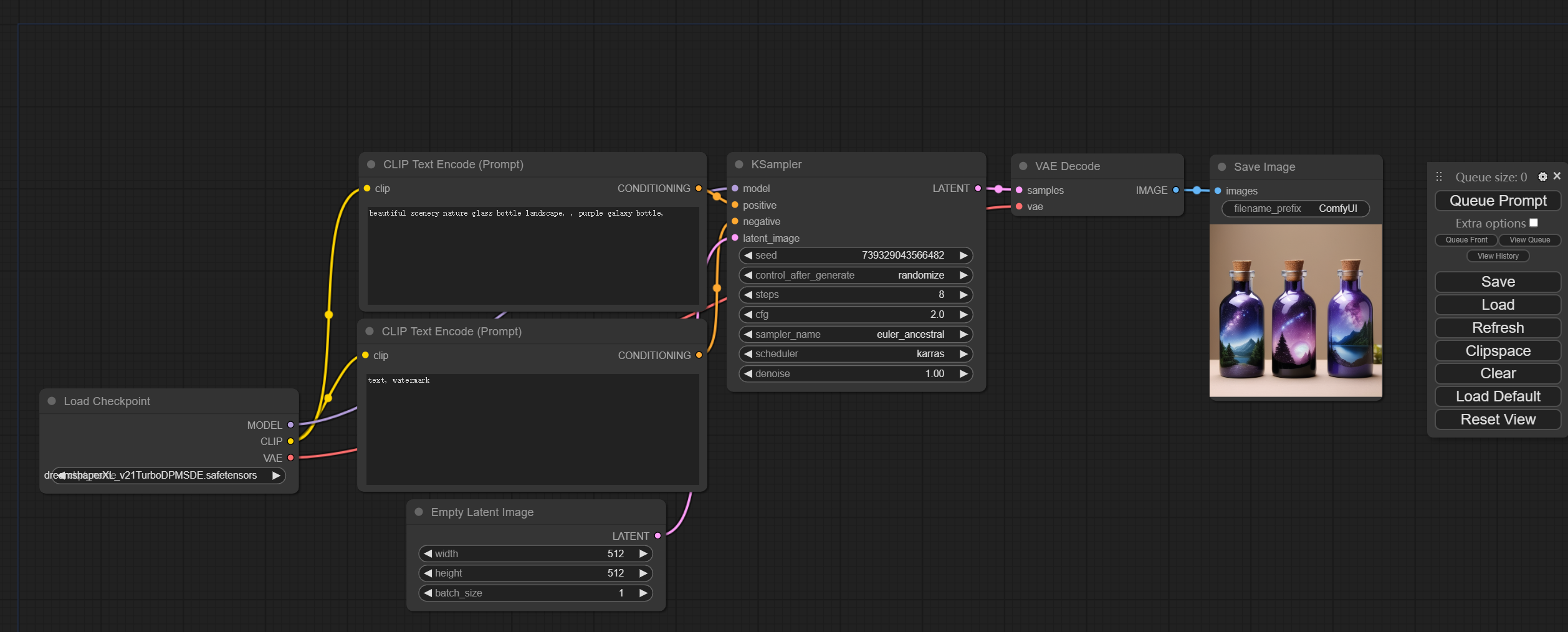
运行成功之后即可看到精美的图片已经生成了。

- 修改参数
接下来可以尝试修改参数,比如修改第一个提示词为:
cinematic film still, close up, photo of redheaded girl near grasses, fictional landscapes, (intense sunlight:1.4), realist detail, brooding mood, ue5, detailed character expressions, light amber and red, amazing quality, wallpaper, analog film grain, jacket第二个提示词修改为:
(low quality, worst quality:1.4), cgi, text, signature, watermark, extra limbs, cleavage将图片大小修改为768x1024: 如下图所示: 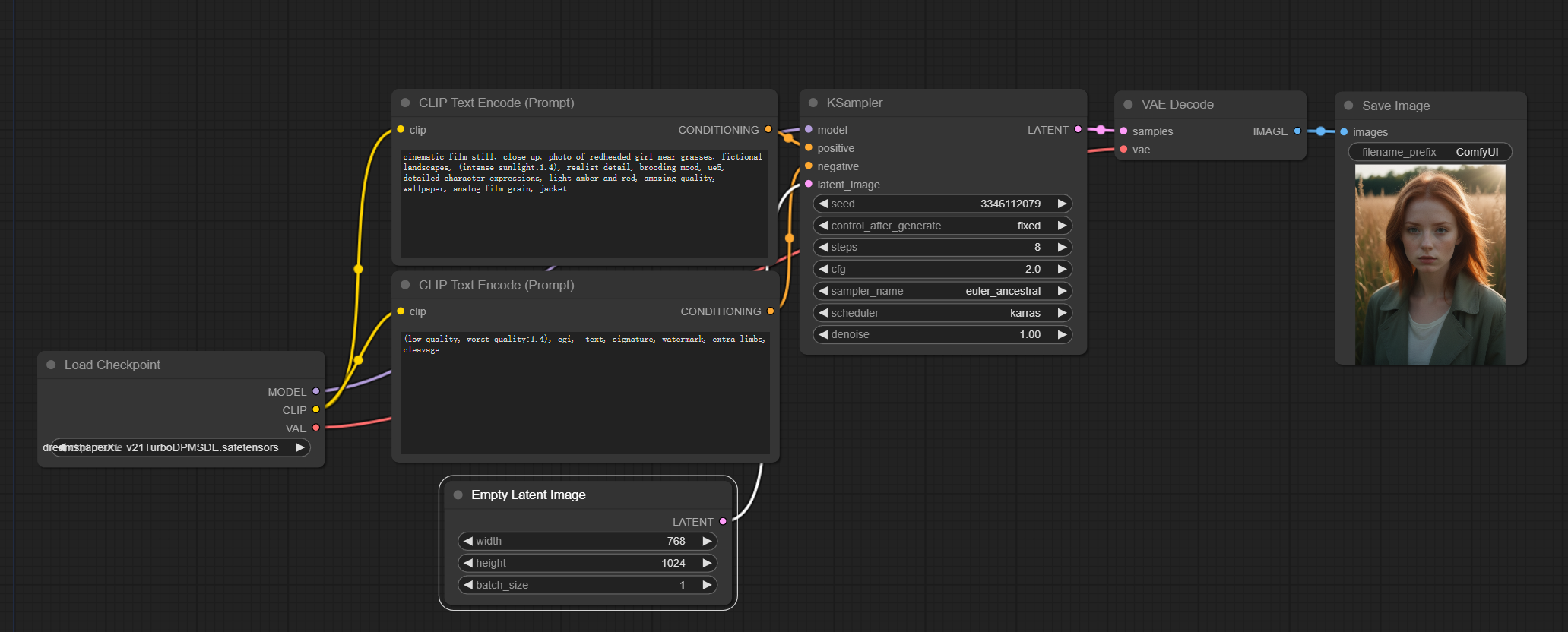 之后再次点击生成按钮,即可看到最新的生成结果。
之后再次点击生成按钮,即可看到最新的生成结果。 
可以说是相当惊艳了。
下一期将探索ComfyUI的更多能力,使用自定义节点创建工作流,完成自定义的文生图任务。 如老旧照片修复,黑白图片上色,真人照片转动漫风格等。
敬请期待~
有任何问题,可以评论区留言讨论。



